Sectors, Coalescing and Vector Loads in CUDA
Memory coalescing occurs when all threads in a warp access a contiguous chunk of data from global memory.
The CUDA C++ Best Practices guide states this in a more precise way:
... the concurrent accesses of the threads of a warp will coalesce into a number of transactions equal to the number of 32-byte transactions necessary to service all of the threads of the warp.
For example, if all threads in a warp were each loading a single float (starting from a 32-byte aligned address), we would end up with 32 threads * 4 bytes = 128 bytes / warp = 4 32 byte transactions. This 32-byte aligned chunk of memory is called a sector.
We can understand the relationship between memory instructions and sectors with the following (from the Nsight Systems Compute Guide):
When an SM executes a global or local memory instruction for a warp, a single request is sent to L1TEX. This request communicates the information for all participating threads of this warp (up to 32). For local and global memory, based on the access pattern and the participating threads, the request requires to access a number of cache lines, and sectors within these cache lines.
Therefore the relationship between a request and a sector is many-to-one. In the above case of perfectly aligned access, we would have 4 sectors / request.
This topic recently came up for me in the context of vectorized loads (LDG.128 and STG.128 in SASS). I mistakenly thought that since I had replaced all my Global -> Shared instructions with vectorized loads that I would be able to achieve peak memory bandwidth, even without taking memory coalescing into account. This was not the case and prompted me to look into the relationship between coalescing and vectorized loads.
A simplified example
To examine this in more detail, we can use a simple kernel, matrix-level SAXPY: x[m,k] = a * x[m,k] + y[m,k] on row-major data. All tests are performed with 4096 x 4096 matrices.
Coalesced Access and Vectorized Instructions
The coalesced and vectorized kernel is as follows:
__global__ void saxpy_coalesced(float *xs, const float *ys, int M, int K, float a) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int nthreads = blockDim.x * gridDim.x;
float4 xsReg;
float4 ysReg;
int start = tid * 4;
int step = nthreads * 4;
int numel = (M * K);
for (int i = start; i < numel; i += step) {
xsReg = *(float4 *)(xs + i);
ysReg = *(float4 *)(ys + i);
xsReg.x = a * xsReg.x + ysReg.x;
xsReg.y = a * xsReg.y + ysReg.y;
xsReg.z = a * xsReg.z + ysReg.z;
xsReg.w = a * xsReg.w + ysReg.w;
*(float4 *)(xs + i) = xsReg;
}
}
If we look at the thread behaviour for the first warp and threadblock:
- thread0 loads
xs[0][0..3] - thread1 loads
xs[0][4..7] - thread2 loads
xs[0][8..11] - ...
Each thread will load 16 bytes of data from global memory so the total amount of a data a single warp loads will be 16 bytes * 32 threads = 512 bytes / warp. Breaking this down by sector, we have:
- data for thread0 and thread 1 is contained in a single sector -> one transaction
- data for thread2 and thread 3 is contained in a single sector -> one transaction
- ...
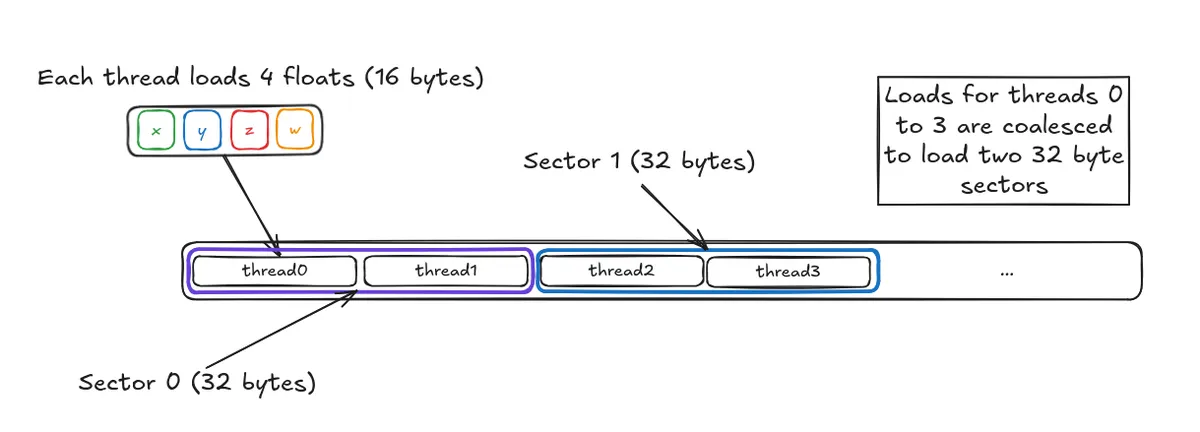
Therefore, we expect that these requests will coalesce into loading 16 different sectors, each of 32 bytes. We can check this with Nsight which confirms this if we look at the Sectors/Req column for both Global Load and Global Store (last column):

On my RTX 4070, this kernel attains close to Speed of Light memory throughput, hitting 91% of the throughput (463 GB/s).
Strided Access and Vectorized Instructions
The uncoalesced kernel uses a column-major access pattern:
__global__ void saxpy_strided(float *xs, const float *ys, int M, int K, float a) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int nthreads = blockDim.x * gridDim.x;
float4 xsReg;
float4 ysReg;
int start = 4 * tid;
int step = 4 * nthreads;
int numel = (M * K);
for (int i = start; i < numel; i += step) {
// col major access
int col = (i) / K;
int row = (i) % K;
int strided_offset = col * 4 + row * K;
xsReg = *(float4 *)(xs + strided_offset);
ysReg = *(float4 *)(ys + strided_offset);
xsReg.x = a * xsReg.x + ysReg.x;
xsReg.y = a * xsReg.y + ysReg.y;
xsReg.z = a * xsReg.z + ysReg.z;
xsReg.w = a * xsReg.w + ysReg.w;
*(float4 *)(xs + strided_offset) = xsReg;
}
}
Looking at the threads in the first warp:
- thread0 loads
xs[0][0..3] - thread1 loads
xs[4][0..3](16384 bytes from thread0) - thread2 loads
xs[8][0..3](16384 bytes from thread1) - ...
While each thread will still issue the same number of 16-byte load instructions, at a sector-level, half the data in each sector loaded will be unused (since we only end up using the first 16 bytes in each sector).
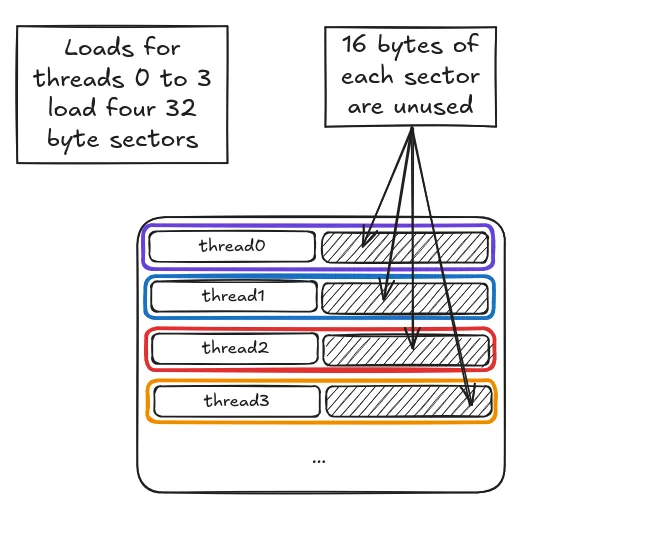
Given this worse pattern, we would therefore expect to load double the number of sectors per memory request (32 versus 16). Once again, Nsight confirms that this kernel loads 32 sectors per request:

This kernel is significantly slower and achieves only 25% of the throughput (132 GB/s)1.
Conclusion
Coalescing behaviour is more complicated than I originally thought, but by working through a simple example, we have gained a deeper understanding of what coalescing is and why it is important, even in the context of wide loads. There are a still a few questions that remain for me though:
- Why is the kernel throughput 25% of the optimal kernel and not halved? This may have to do with the fact that the L1TEX cache lines are 128 bytes.
- Is there a "sweet-spot" in between fully coalesced and partially coalesced where we can still attain full performance? As a quick test, I tried a "pairwise thread" layout where threads k and k+1 will issue vectorized loads to contiguous addresses in memory but didn't see much of an improvement.
TL;DR: While vectorized instructions decrease the total number of instructions issued by the GPU, the actual number of pieces of data fetched (sectors) from memory will depend on the layout of the request. This cannot be overlooked for writing performant kernels.
Code for all experiments is available here.
I do not understand why doubling the total sectors fetched ends up quartering the performance. Clearly, I still have more to learn.↩