Implementing a 2:4 Sparse GEMM Kernel with Tensor Cores
TL;DR: I have spent the last few months learning about and implementing a 2:4 bfloat16 Sparse GEMM kernel in CUDA. On a range of (nice) problem sizes it achieves between 94% and 98% the throughput of cuSPARSE. There are many excellent posts covering dense GEMM optimization in CUDA, building up the final kernel piece-by-piece, this post is not that. Instead, we will provide an overview of how sparse tensor cores work and then go over the details of the sparse GEMM kernel.
The kernel code discussed in this post is available on Github
An overview of 2:4 Sparse Tensor Cores and Sparsity
Since Ampere (sm80), NVIDIA GPUs include sparse tensor cores which can accelerate an MxNxK GEMM if the reduction dimension (K) of either the LHS or RHS operands, is "2:4 Sparse". "2:4 sparse" means that in every block of four contiguous values, two of them are identically zero. In these situations, a sparse GEMM can theoretically achieve twice the throughput of the equivalent dense GEMM.
Note: For the rest of this post, we will consider the case A @ B, where A and B are row-major in global memory and A is 2:4 sparse along the column dimension.
When working with sparse matrices, storing the zeros is redundant. There are many distinct storage formats that can be used to store a compressed representation of the sparse matrix. At their core, these methods use multiple arrays to represent the matrix, one array for the non-zero matrix data and one (or more) additional arrays to represent the locations of the non-zero values in the "full" matrix. This link gives a nice overview of some common sparse storage formats.
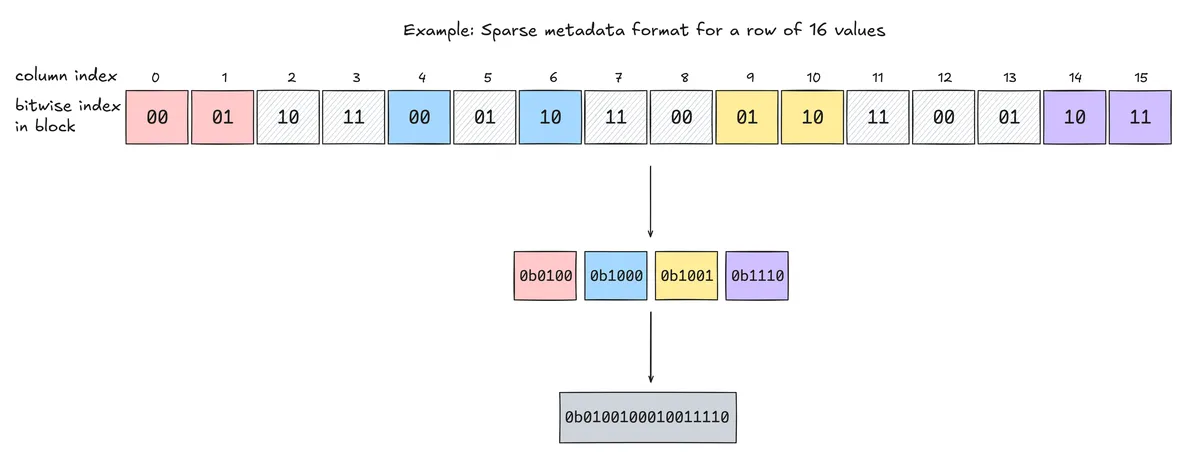
NVIDIA tensor cores use a custom storage format, similar to ELLPACK which stores the non-zero values of the sparse matrix as one array and its positional information in another array. Given a bfloat16 MxK matrix A, we define two matrices, a bfloat16 matrix ASp and uint16 matrix Meta. ASp is of size Mx(K/2) and just stores the non-zero values contiguously. Meta is of size Mx(K/16). Each uint16 encodes, for 16 consecutive columns of A, the positions of the 2 nonzeros in each 4-element group (8 positions total x 2 bits each).
Meta
Given four contiguous values of a 2:4 sparse array, we can represent their indices within this array using 2 bits for each index value. For example, the array [0,2.1,-8.9,0] can be indexed as [00,01,10,11]. From this block, we extract the two indices of the non-zero indices, 01 and 10. The PTX instructions we use require the indices in the sparsity metadata to be sorted. The smaller 2-bit index goes in the low bits; the larger goes in the next 2 bits, so we would represent these non-zero indices for this block as 1001. This of course, only yields four out of the sixteen bits we need so we pack four contiguous columns of these together to yield a sixteen bit unsigned short.
At this stage, we now have the two arrays needed to represent our matrix, ASp and Meta.
mma.sp PTX Instructions
NVIDIA has support for sparse tensor core GEMMs through the mma.sp.* PTX instructions. Unlike non-sparse tensor cores, there is no CUDA wmma API and the instructions must be used through inlined PTX. For our inputs and outputs, there are two instructions we can use mma.m16n8k16 and mma.m16n8k32. In both of these cases, the k{32,16} dimension counts the length of the reduction dimension for the non-sparse operand (ex: in mma.m16n8k32, ASp will be 16 x 16 and B will be 32 x 8). There are also two variants for each of these instructions: mma.sp::ordered_metadata and mma.sp. The former requires the indices in the sparsity metadata to be sorted in an increasing order starting from LSB, as we have detailed above.
Note: All GEMMs discussed in this post will be using the mma.sp::ordered_metadata.sync.aligned.m16n8k32.row.col.f32.bf16.bf16.f32 instruction.
The actual interface for these instructions is almost identical to that of the non-sparse mma.sync 1 PTX instructions and can be called as follows:
mma_sp_m16n8k32(const unsigned* A, const unsigned* B, float* C, float* D, const u_int e, const u_int selector) {
asm volatile(
"mma.sp::ordered_metadata.sync.aligned.m16n8k32.row.col.f32.bf16.bf16.f32"
"{%0, %1, %2, %3}, "
"{%4, %5, %6, %7}, "
"{%8, %9, %10, %11}, "
"{%12, %13, %14, %15}, %16, %17;\n"
: "=f"(D[0]), "=f"(D[1]), "=f"(D[2]), "=f"(D[3])
: "r"(A[0]), "r"(A[1]), "r"(A[2]), "r"(A[3]),
"r"(B[0]), "r"(B[1]), "r"(B[2]), "r"(B[3]),
"f"(C[0]), "f"(C[1]), "f"(C[2]), "f"(C[3]), "r"(e), "r"(selector));
}
The two additional arguments not found in mma.sync.* instructions come from the two additional arguments, u_int e and u_int selector. This mma.sp instruction assumes that the LHS matrix of size 16 x 32 is 2:4 sparse (so when packed it will have 16 columns). For this, we also need to provide the metadata for the non-zero values, which require a total of 16 x 4 x 8 additional bits. A thread-pair within a group of four consecutive threads holds the metadata. When selector is 0, then the thread pairs t0/t1, t4/t5, t8/t9, ..., t28 / t29 hold the sparse metadata and when selector is 1, the other thread pairs will hold the metadata (t2/t3, t6/t7, ...). This distribution ensures that each of the participating threads will hold an additional 32 bits. These 32 bits are bit-packed together from two unsigned shorts coming from the Meta array.
The Sparse Metadata layout diagram is taken from here. We add explicit row / column annotations for the bits that the first and second threads in a pair will load:
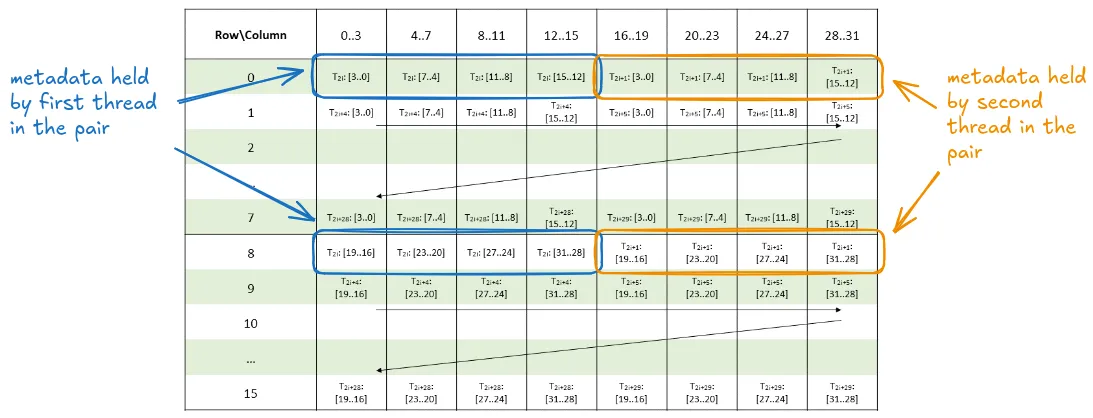
Note: An astute reader will notice that the thread : data layout is far from ideal. The current mapping is not compatible with any ldmatrix instruction, nor can it be loaded in a coalesced fashion. More on this later...
Implementation Details
The discussion of the actual GEMM can be broken down into two sections:
- The layout and structure for computing the actual GEMMs on the dense matrices (
ASpandB) - The layout and structure for loading and using the Metadata array
GEMMs
The layout of the actual GEMM computation is fairly standard and the exact problem sizes were determined from hand-tuning different block shapes and sizes. The resulting GEMM has the following characteristics:
- Launches 128 threads per threadblock, computing an output tile of size
128x128x64 - The four warps in the thread block are arranged in a row-major ordering and each warp computes its own
64x64x64subtile. - Each warp executes a total of 64
mma.sp::ordered_metadata.sync.aligned.m16n8k32.row.col.f32.bf16.bf16.f32instructions. - A three-stage
cp.asyncpipeline is used to load all matrices from global to shared memory. - Data copies from shared memory to registers are double-buffered.
The structure of this part of the GEMM was derived from a combination of the following two resources Implementing a fast Tensor Core matmul on the Ada Architecture and CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining as well as reading through NVIDIA Nsight Compute (NCU) profiles for both cuSPARSE and CUTLASS kernels to identify their threadblock layouts and instruction mixes.
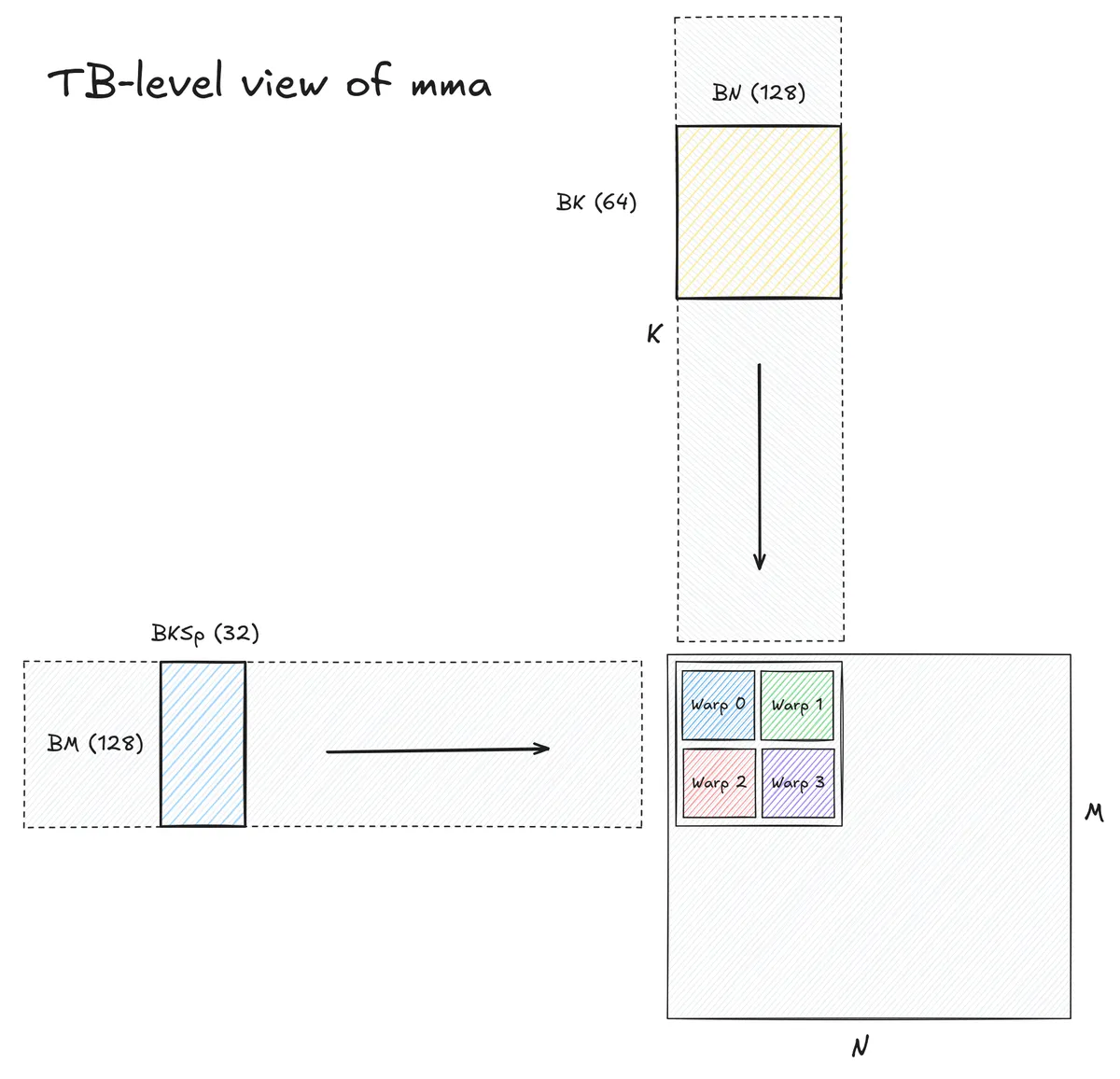
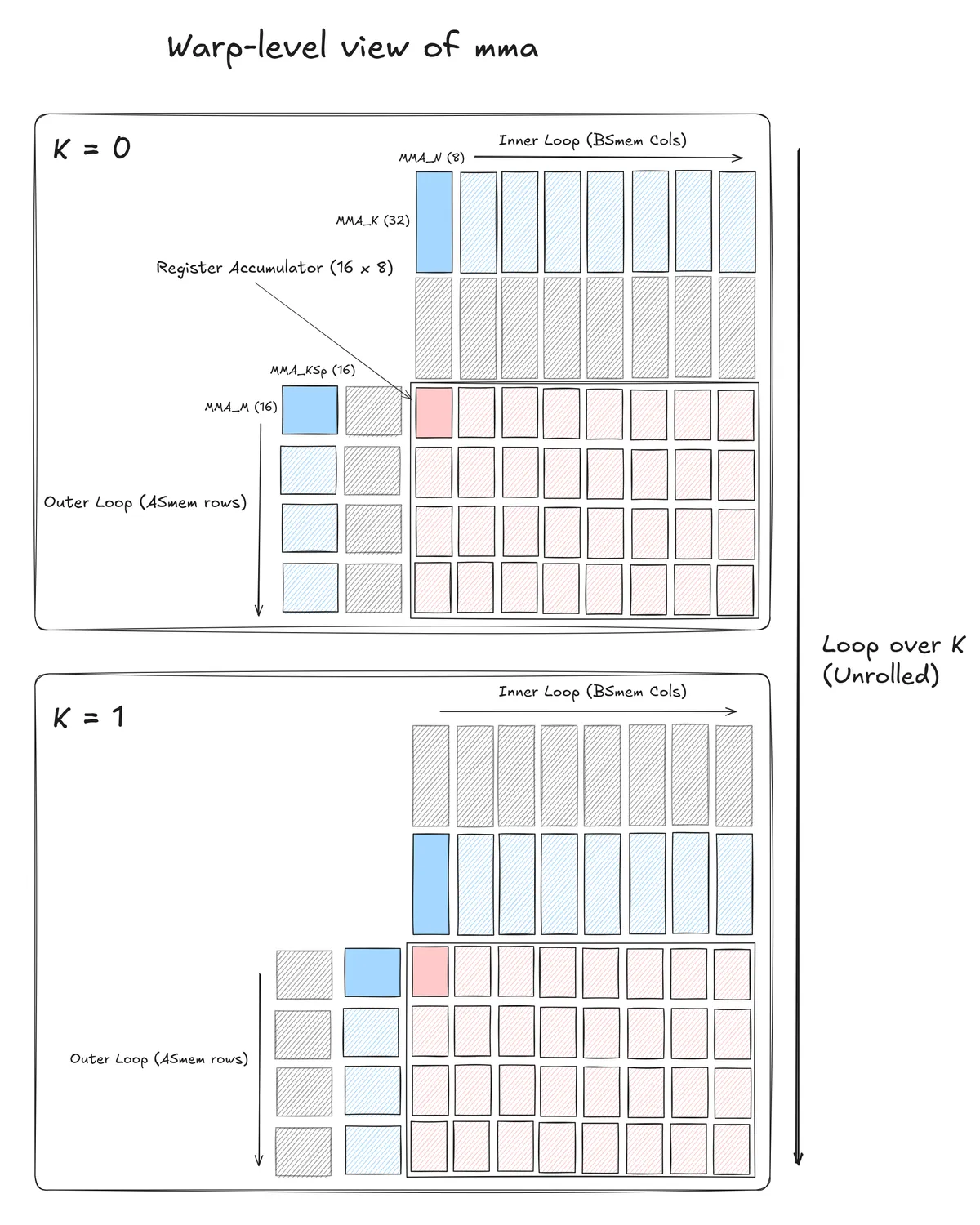
Metadata
The non-standard part of this kernel is the Metadata load. All tensor core GEMMs use specific instructions to load the matrix fragments from shared memory to registers. As the mapping between shared memory and register fragments is not contiguous within a warp, these memory transactions are uncoalesced leading to slow load performance. To get around this, we have the ldmatrix instruction, whose purpose is to facilitate the matrix fragment loads more efficiently. The smallest ldmatrix instruction, ldmatrix.x1 will load an 8x8 tile of 16 bit values to registers.
The specification for ldmatrix can get complicated, but for our purposes, the main things we need to keep in mind about it are:
- For 16-bit loads, the 128 bits of the matrix fragment we load from must be contiguous in shared memory.
- Consecutive instances of the rows need not be stored contiguous in memory.
The ldmatrix instruction loads values according to the layout:
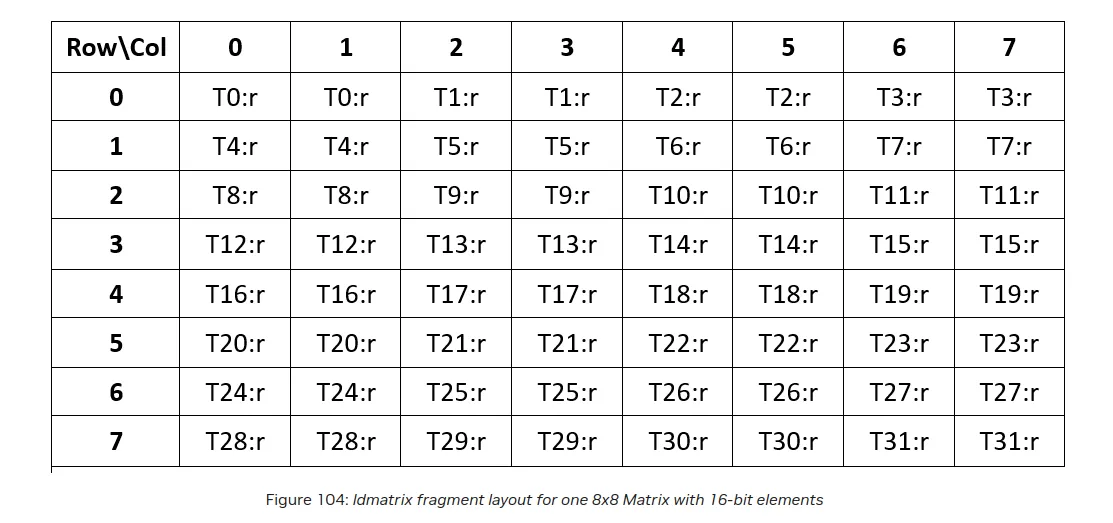
while the Metadata array has the following layout:

There are three immediate issues with this layout:
- We don't even have enough values for a single
ldmatrixinstruction (this metadata layout specifies 32 total values but we need 64 for theldmatrixinstruction) - Only half the threads are used
- The column mapping is not correct as each loaded row is not contiguous in memory
We can solve the first and second issues immediately by ensuring that our MMAs will use a combination of the sparsity selector for thread pair (t0/t1) and thread pair (t2/t3). The first block of MMAs will use the first thread pair and the second will use the second thread pair
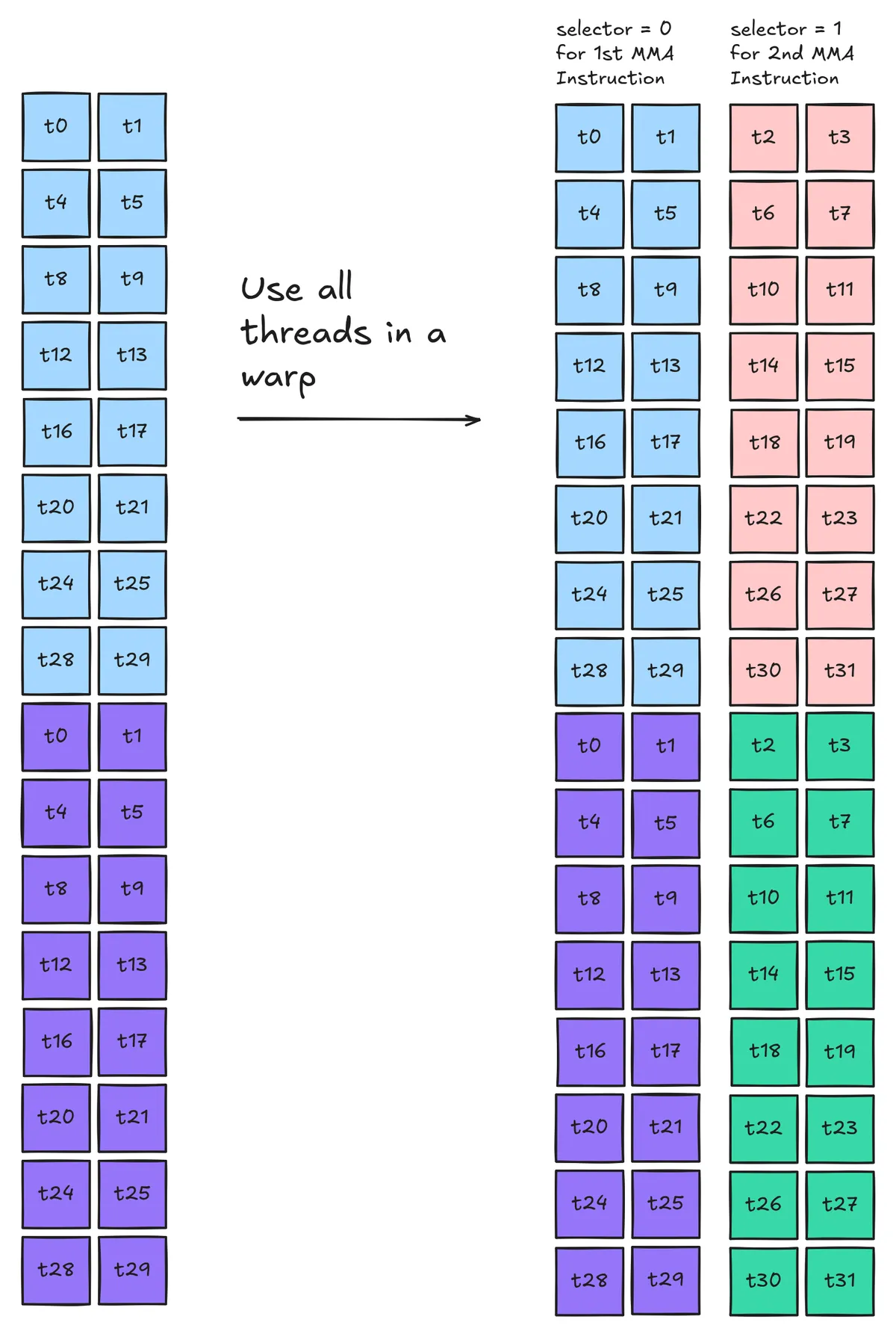
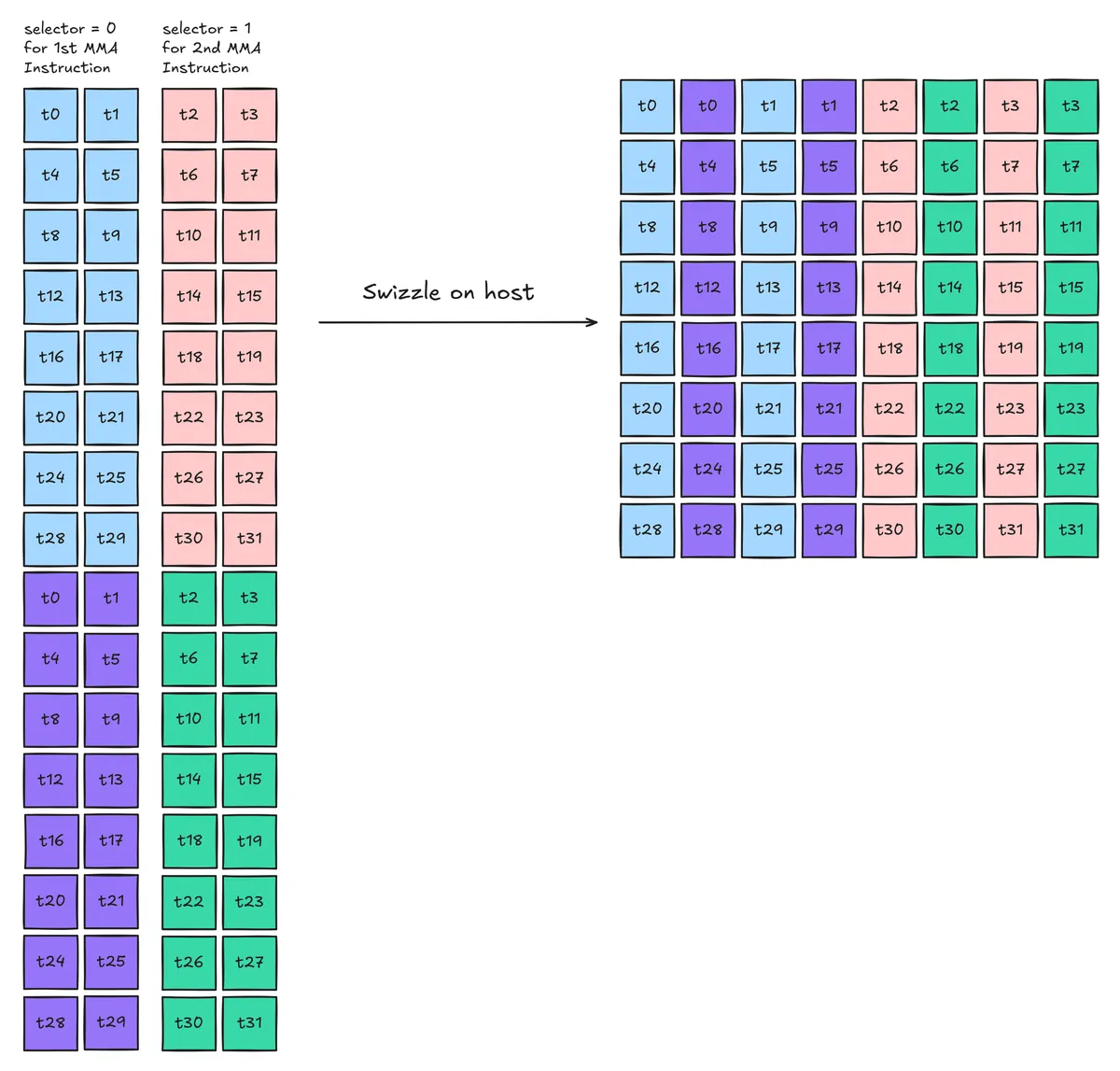
We can solve this final issue by pre-swizzling the metadata layout to align with the requirement for ldmatrix instructions:
There are relatively few resources for high performance sparse tensor cores online. These optimizations came through a combination of reading through MARLIN: Mixed-Precision Auto-Regressive
Parallel Inference on Large Language Models which has a section on a sparse tensor cores and reading through NCU profiles for cuSPARSE and CUTLASS kernels. The idea of using ldmatrix for the metadata loads comes from MARLIN, where they use a similar swizzle strategy in their Sparse-MARLIN kernel for loading the metadata to registers. Using both thread pairs for the sparse metadata came after I noticed that all cuSPARSE and CUTLASS kernels had SASS that looked like this (my comments added):
...
HMMA.SP.16832.F32.BF16 R52, R152, R160, R52, R3, 0x0 // mma with t0/t1
HMMA.SP.16832.F32.BF16 R56, R152, R164, R56, R3, 0x0 // mma with t0/t1
HMMA.SP.16832.F32.BF16 R60, R156, R160, R60, R3, 0x1 // mma with t2/t3
...
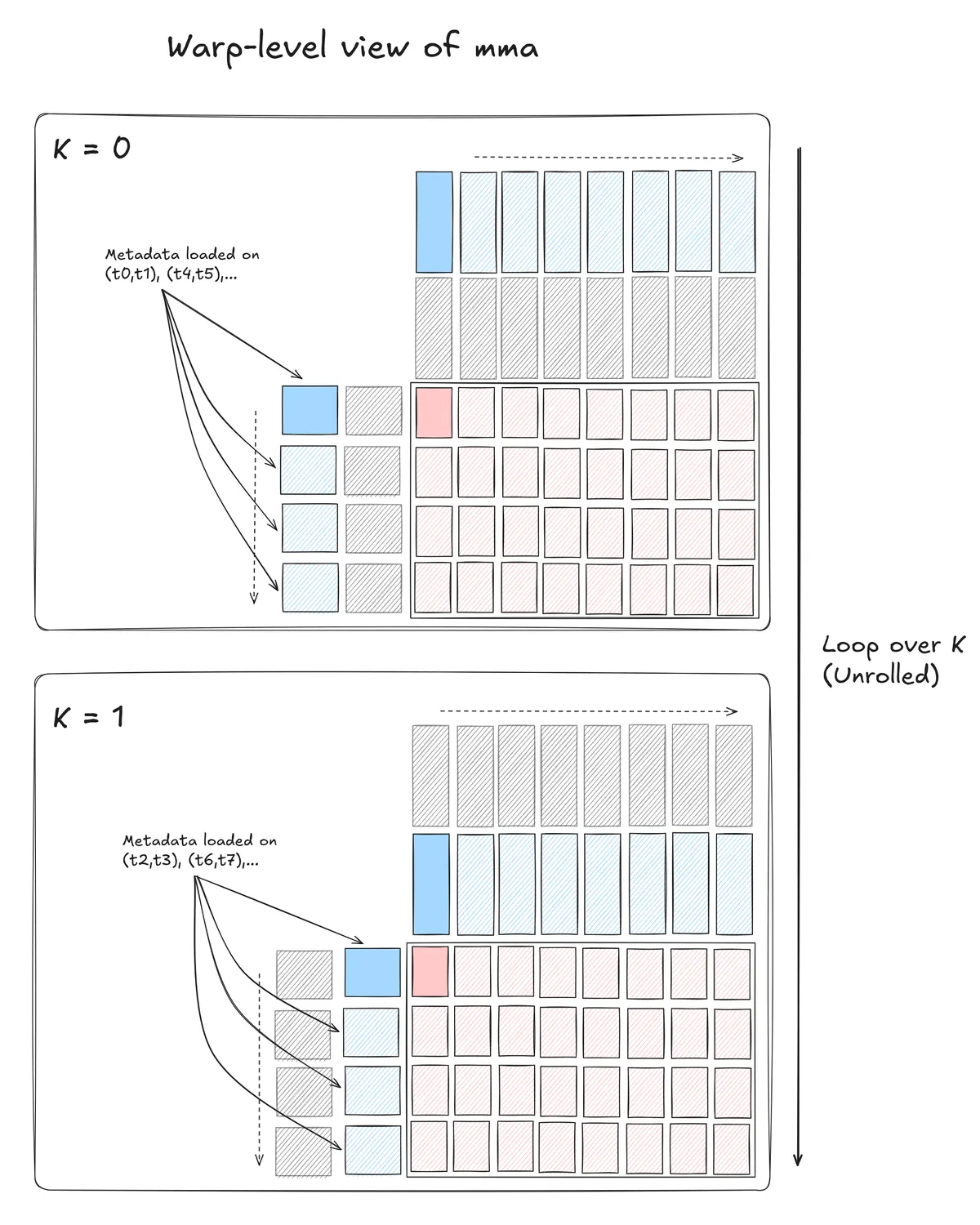
With this swizzle, we can now load all the metadata required for 2 consecutive mma.m16n8k32 instructions (along the reduction dimension). As the warp-level MMA computes an output tile with 64 rows, we use an ldmatrix.x4 instruction to load all the metadata required for the warp-level MMA with a single instruction. The swizzle code for this is currently computed on the host prior to starting the actual GEMM.
Revisiting the above warp-level diagram, we have:
The final piece we need is to determine how we will handle the loads from global memory to shared memory. As all code for this post was written for an Ada (sm89) device, we won't be using Tensor Memory Accelerator (TMA) instructions. The global to shared loads for ASp and B are handled as expected with the standard cp.async pipeline. We use a 3-stage pipeline to hide the latency which limits our kernel's occupancy to 1 thread block per SM, but is the best performing configuration.
The explicit instruction we use for these loads is cp.async.cg.shared.global.L2::128B [%0], [%1] 16 which issues the full-width 16-byte loads and prefetches 128 bytes to L2 cache (L2::128B) while caching the data only at the L2 level (cg). The important part of this to note is the .cg cache-policy, setting this to ca so the data is cached at L2 and L1 incurs a throughput penalty of around 10% as it introduces bank conflicts. This distinction is important. For loading the Metadata array to shared, we want to load a total of 64 rows x 8 columns2 = 512 16-bit values across all threads. If we want every thread in our block to participate then each thread should issue a 64 bit cp.async load. That's easy, we can just change the 16 in the above cp.async instruction to 8 and we're good to go ...right? Unfortunately this doesn't work. A careful read through the code example will show that the cg specifier can only be set with the full 16-byte loads, for some reason, this isn't actually explained in the documentation anywhere aside from the code example. This means that if want to use the 8 byte cp.async load, we will always run into bank conflicts that cannot easily be resolved.
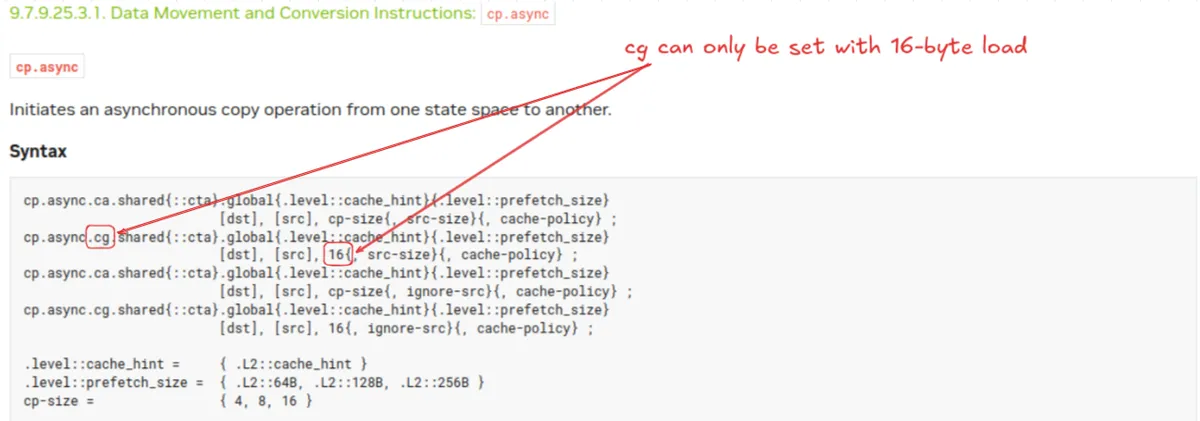
We can look at the SASS instructions for both cuSPARSE and CUTLASS to identify what they do to fix this. cuSPARSE accepts the banks conflicts and uses both the LDGSTS.E.LTC128B.64 and LDGSTS.E.BYPASS.LTC128B.128 instructions. CUTLASS, however, takes a different approach by only issuing the non bank-conflicted LDGSTS.E.BYPASS.LTC128B.128 instruction on half the threads in a thread block. This is the approach we take as well, all even numbered threads in a thread block load the metadata array while the odd numbered threads do not issue any instruction 3.
Benchmarks
Benchmarking is performed against cuSPARSE kernels on an RTX 40704. The GPU's SM and memory clocks were locked to their peak values and benchmarking was performed over 250 iterations with the first 50 iterations discarded as warmup iterations. We follow Triton's do_bench and clear the L2 cache between runs of the kernel. On my fork of mmapeak, I was able to determine that the sparse tensor core throughput for my hardware is 122.3 TFLOPs, or double the dense throughput of 61.2 TFLOPs.
At problem size 4096x4096x4096, we achieve 98% the throughput of cuSPARSE (100.1 TFLOPs/s vs 98.3 TFLOPs/s):
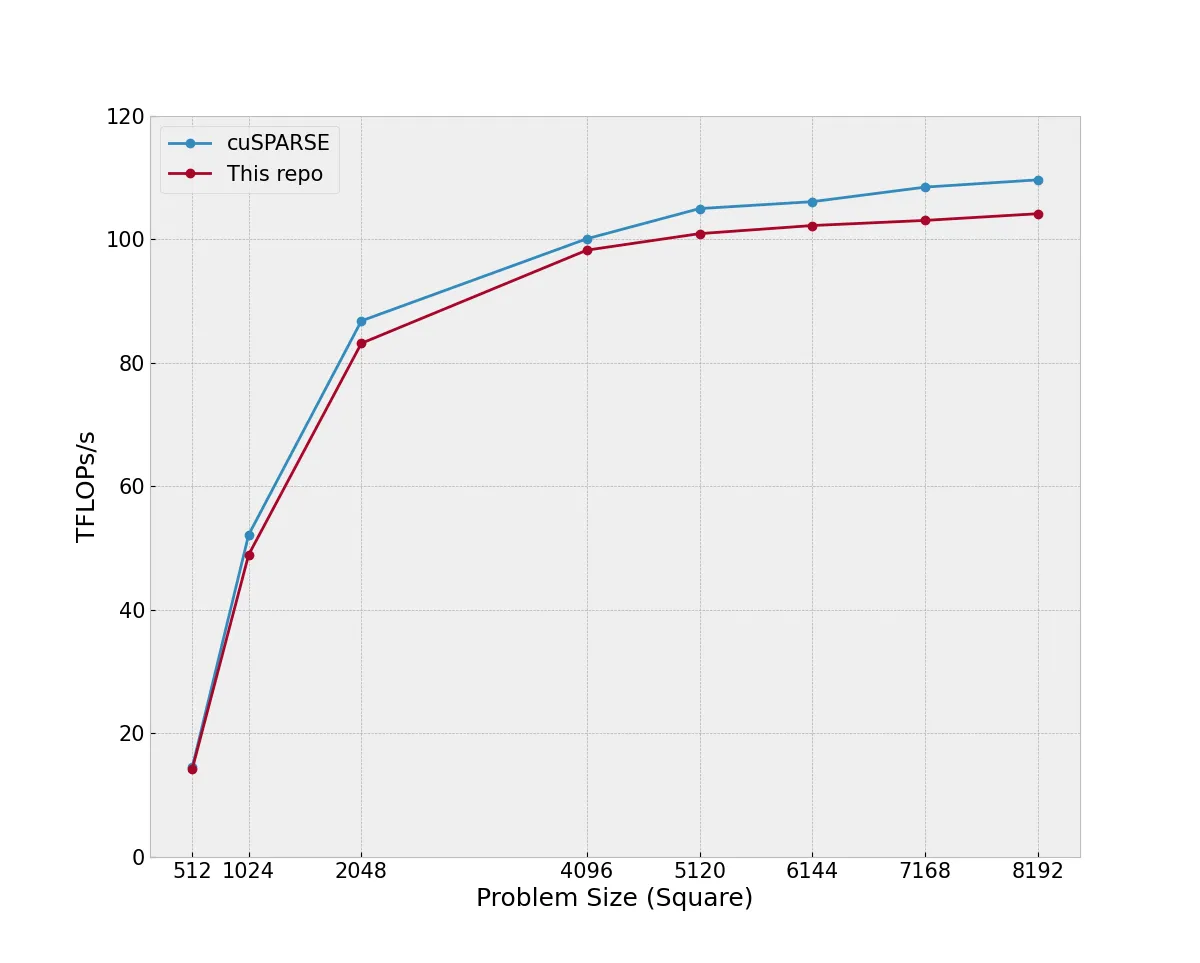
For smaller and larger GEMM sizes, we lose some performance as cuSPARSE is able to select the best kernel from many different configurations. At worst we achieve 94% the throughput of cuSPARSE with an 8192x8192x8192 GEMM (109.6 TFLOPs/s vs 104.2 TFLOPs/s).
Conclusion
Writing this kernel revealed several non-obvious optimizations, particularly around metadata loading, that aren't well-documented elsewhere. This is where I'll close out my work on this for now but if I had more time, there are a few avenues I could pursue to extend this work:
- Dimension masking for arbitrary problem sizes: The M,N, and K dimensions for this kernel must be divisible by 128, 128, and 64 respectively. Future work could implement kernels to support any problem size.
- Building a family of kernels and writing an autotuner: As we saw, our kernel's performance starts to lag behind cuSPARSE for larger problem sizes. Parameterize the kernel arguments (ex: threads, warps, block sizes, pipeline depth) in such a way that we can generate multiple correct kernels and then select the best kernel for a given problem size.
- Further optimization for the Metadata loads to registers: When reading through the SASS for some of the fastest cuSPARSE and CUTLASS kernels, I noticed some of them use
ldmatrix.x2instructions for the metadata load, while my kernel only usesldmatrix.x4. Why is this? A theory I have is that this could be that this is used as a form of double-buffering, but more investigation is needed here.
For a good overview of dense
mma.syncinstructions, I like this post.↩64 rows x 8 columns comes since we have pre-swizzled the Metadata array offline.↩
Another layout option would be to specify that only the first and second warps issue all the loads to minimize warp divergence. I tried this method briefly but the performance was worse.↩
We follow standard benchmark practice and compute the FLOPs as
2xMxNxK, even though we end up only performingMxNxKoperations.↩